Probleme bei der Softwarebereitstellung treten selten plötzlich auf.
Wenn ein Projekt eindeutig unter regelmäßigen Verzögerungen leidet, sind die sichtbaren Symptome meist schon seit einiger Zeit vorhanden. Sprintziele werden begonnen und verschieben sich immer weiter. Schätzungen werden zunehmend unzuverlässig. Einfache Änderungen dauern länger als erwartet. Das Team wird vorsichtiger. In Bereichen, die eigentlich schon stabil sein sollten, treten mehr Fehler auf – als Folge von Änderungen in anderen Bereichen. Releases erfordern mehr Abstimmung, als sie eigentlich sollten.
Von außen oder auf den ersten Blick kann das sehr wie ein Lieferproblem aussehen.
Die Führungsebene fragt sich vielleicht, warum das Team nicht schneller vorankommt, warum Schätzungen ungenau sind, warum Entwickler immer wieder an denselben Teilen des Systems arbeiten oder warum jede neue Funktion scheinbar unerwartete Nebenwirkungen hat.
Das sind natürlich berechtigte Fragen, aber sie zielen oft auf die falsche Ebene ab.
In vielen Fällen wird das Lieferproblem nicht in erster Linie durch mangelnden Einsatz, schwache Entwickler oder schlechtes Aufgabenmanagement verursacht. Die eigentliche Einschränkung ist oft architektonischer Natur. Das System hat einen Punkt erreicht, an dem seine Struktur das Tempo, die Sicherheit oder die Klarheit, die das Unternehmen von ihm erwartet, nicht mehr unterstützt.
Das ist eine heikle Phase, weil das Projekt noch sehr aktiv wirken kann. Es wird gearbeitet. Pull Requests werden zusammengeführt. Meetings finden statt. Das Backlog bewegt sich. Doch unter all dieser Aktivität steigen die Kosten all dieser Veränderungen immer weiter an.
Das Team entwickelt nicht mehr einfach nur Funktionen; es muss ständig mit der Architektur verhandeln und gegen sie ankämpfen.
Wenn die Architektur die Auslieferung nicht mehr unterstützt, wird jede Änderung teurer, als sie zunächst erscheint.
Diese Situation ist für CEOs, CTOs, Engineering Manager und Projektleiter wichtig, weil architektonische Lieferprobleme nicht lange rein technisch bleiben. Sie führen zu verpassten Zusagen, einer langsamen Reaktion auf Marktanforderungen, wiederholt fragilen Releases, einer steigenden Zahl von Incidents, frustrierten Teams und schließlich zu einem unnötigen Vertrauensverlust zwischen Business und Engineering.
Je früher diese Signale erkannt werden, desto leichter lassen sie sich korrigieren.
Das verbreitete Missverständnis über Architektur
Architektur wird oft zu abstrakt diskutiert.
Es wird als technische Präferenz behandelt, als optionaler Schritt in der Entwicklung, als Diagramm, als Framework-Entscheidung oder als etwas, worüber Senior Engineers diskutieren, während das Business auf die Auslieferung wartet. So sollte man nicht darüber denken, und Unternehmen, die das tun, setzen sich unnötigen Risiken und dem Scheitern aus.
Die Architektur in der Software definiert einen Betriebsrahmen mit Einschränkungen, ähnlich wie die Architektur eines realen Gebäudes vorgibt, was mit dem Gebäude möglich ist und wie einfach sich daran Änderungen vornehmen lassen.
Die Softwarearchitektur bestimmt, wie leicht ein Team Änderungen vornehmen, Risiken eingrenzen, Verhalten testen, Entwickler einarbeiten, mit anderen Systemen integrieren und sich von Fehlern erholen kann. Gute Architektur bedeutet nicht, dass das System nach irgendeinem theoretischen Maßstab elegant ist. Sie bedeutet, dass das System es dem Unternehmen ermöglicht, sich weiterzuentwickeln, ohne dass jede Änderung unverhältnismäßig riskant oder langsam wird oder Teile der Software beeinträchtigt, die eigentlich nicht betroffen sein sollten.
Schlechte Softwarearchitektur ist nicht immer so offensichtlich wie schlechter Code.
Manchmal ist der Code für sich genommen völlig verständlich und funktioniert einwandfrei. Das Problem liegt in der Struktur des Systems: unklare Grenzen, verborgene Abhängigkeiten, doppelte Geschäftsregeln, unzuverlässige Verträge und Lücken in der Zuständigkeit zwischen Modulen, Teams oder Anbietern.
Deshalb werden Architekturprobleme so oft unterschätzt oder sogar gar nicht erkannt.
Eine einzelne Verzögerung bei einem Feature mag wie ein lokales Lieferproblem erscheinen. Doch wenn jede Feature-Verzögerung demselben Muster folgt, ist das Problem nicht mehr lokal. Das System liefert Ihnen diese Information tatsächlich.
Die Führung sollte dies beachten, bevor die Organisation mit der falschen Maßnahme reagiert.
- Mehr Druck wird unklare Grenzen nicht beheben.
- Mehr Entwickler einzusetzen, kann die Abhängigkeitsverflechtung noch verschlimmern.
- Mehr Projektmanagement wird Verträge, denen niemand vertraut, nicht ausgleichen.
- Mehr QA am Ende wird keine Probleme mit einem System lösen, das sich nicht sauber testen lässt.
Die richtige Maßnahme beginnt damit, die architektonischen Anzeichen frühzeitig zu erkennen.
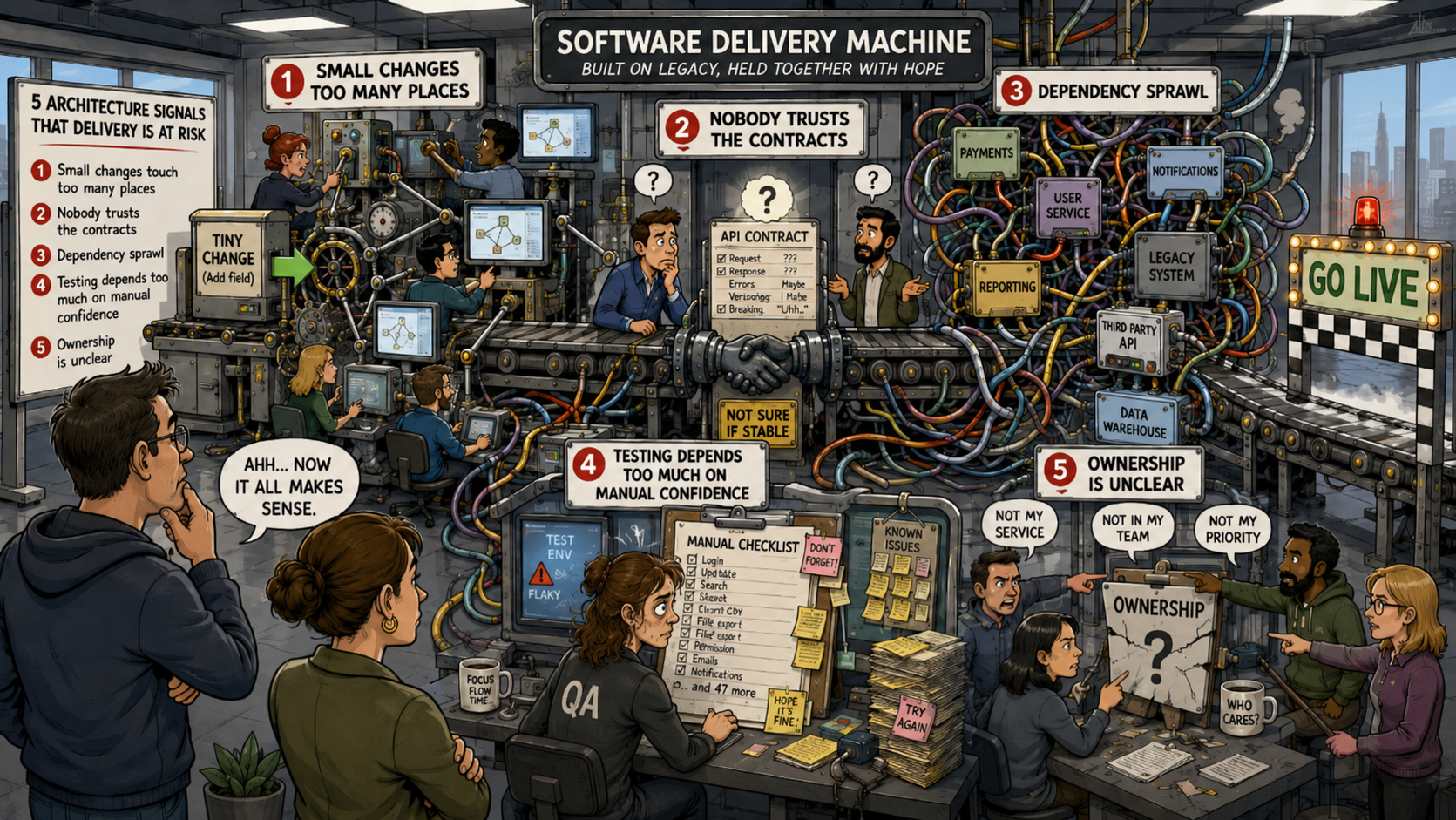
Signal 1: Kleine Änderungen erfordern Änderungen an zu vielen Stellen
Eines der deutlichsten Anzeichen für Probleme bei der Bereitstellung ist, wenn kleine Änderungen im Geschäft Anpassungen in zu vielen Teilen des Systems erfordern.
Eine Preisregel ändert sich, aber sie beeinflusst Angebote, Rechnungen, Berichte, Berechtigungen, Benachrichtigungen und mehrere Hintergrundjobs.
Der Status eines Kunden ändert sich, aber das Team muss fünf verschiedene Stellen prüfen, in denen die Statuslogik teilweise dupliziert ist.
Eine neue betriebliche Ausnahme wird eingeführt, aber niemand ist sich ganz sicher, welche Arbeitsabläufe davon betroffen sein werden.
Das ist mehr als nur eine Unannehmlichkeit. Es bedeutet, dass das System keine klare Verantwortlichkeit für seine Geschäftskonzepte hat.
Wenn sich eine Änderung zu weit ausbreitet, muss das Team Zeit darauf verwenden, alle betroffenen Bereiche zu identifizieren, Nebenwirkungen nachzuvollziehen, Reviews zu koordinieren, Tests zu aktualisieren und das Verhalten manuell zu validieren. Die Auslieferung verlangsamt sich, weil jede Änderung mit verstecktem Analyseaufwand verbunden ist, und Schätzungen werden ungenau, weil es immer schwieriger wird, diesen versteckten Aufwand vorherzusagen.
Die sichtbare Aufgabe mag klein sein - die tatsächliche Reichweite der Veränderung ist groß.
Das deutet meist auf schwache Domänengrenzen hin. Das System ist möglicherweise organisch gewachsen, wobei Geschäftslogik dort ergänzt wurde, wo es damals gerade praktisch war. In der Anfangsphase mag das noch akzeptabel gewesen sein, aber mit dem Wachstum des Unternehmens wird aus Bequemlichkeit Kopplung.
Das Risiko hier ist nicht nur eine langsamere Auslieferung. Das eigentliche Risiko besteht darin, dass das Team irgendwann anfängt, Veränderungen zu vermeiden.
Sie werden auf die falsche Weise vorsichtig, weil sie es müssen. Sie verzögern Verbesserungen, weil sie die Nebenwirkungen nicht vorhersehen können. Sie fügen Patches hinzu, statt die Struktur zu korrigieren. Sie erhalten schlechte Abläufe aufrecht, weil es sich zu gefährlich anfühlt, sie anzutasten.
So wird technische Schuld zu operativer Schuld.
Signal 2: Niemand vertraut den Verträgen zwischen den Teilen des Systems
Ein gesundes System hat klare Grenzen und Verantwortlichkeiten, auf die Teams sich verlassen können.
Ein Modul, ein Service, eine API, eine Integration oder ein interner Prozess sollte einen klaren Vertrag haben: was er erwartet, was er zurückgibt, was Fehler bedeuten, wer dafür verantwortlich ist und auf welches Verhalten sich andere Teile des Systems verlassen können.
Wenn diese Vereinbarungen unklar oder instabil sind, wird die Lieferung zum Verhandlungsthema.
Entwickler müssen die tatsächlichen Implementierungsdetails prüfen, statt sich auf dokumentiertes Verhalten zu verlassen. Teams fragen sich gegenseitig, ob ein Feld immer vorhanden ist, warum manche Felder manchmal optional und manchmal verpflichtend sind, ob ein Status übersprungen werden kann, ob eine Integration automatisch erneut versucht, ob ein Fehler einen Ausfall oder eine Verzögerung bedeutet und ob ein Endpunkt während der Spitzenzeiten sicher aufgerufen werden kann.
Das erhöht nur die Reibung bei jeder Änderung.
Es erzeugt außerdem eine gefährliche Art von Unsicherheit: Das System mag die meiste Zeit funktionieren, aber niemand kann mit Zuversicht erklären, warum es funktioniert, unter welchen Umständen es mit Sicherheit funktioniert, wann es versagt oder worauf sich ein anderes Team verlassen darf.
Das ist ein sehr ernstes Risiko für die Lieferung.
Unklare Verträge sind besonders schädlich in Systemen, an denen mehrere Teams, Anbieter, operative Abläufe oder kundennahe Prozesse beteiligt sind. Jeder unklare Vertrag wird zu einer Koordinationsbelastung. Jede undokumentierte Annahme wird zu einem potenziellen Vorfall. Jeder Fehler führt zu sinkendem Vertrauen und zunehmender Reibung zwischen den Teams.
Die tatsächlichen Geschäftskosten zeigen sich während der Integration, des UAT, der Produktionsfreigaben, des Onboardings und der Reaktion auf Vorfälle.
Ein Team kann unklare Verträge eine Zeit lang durch Erfahrung und informelle Kommunikation ausgleichen. Doch das lässt sich nicht skalieren. Sobald wichtige Personen nicht verfügbar sind, neue Entwickler dazukommen, Anbieter wechseln oder das System wächst, wird verborgenes Wissen zu Instabilität in der Umsetzung führen.
Wenn das Team erst herumfragen muss, bevor es etwas Wichtiges ändert, vermittelt die Architektur nicht genug Wissen.
Signal 3: Die wachsende Abhängigkeit von anderen verlangsamt jede Entscheidung
Abhängigkeitswildwuchs entsteht, wenn zu viele Teile des Systems von zu vielen anderen Teilen abhängen, ohne einen klaren Grund, eine klare Hierarchie oder ein klares Verantwortungsmodell.
Dies kann innerhalb der Codebasis, zwischen Diensten, zwischen Teams oder zwischen Geschäftsprozessen auftreten.
Auf den ersten Blick wirkt es vielleicht nicht so gravierend. Ein paar Abkürzungen werden aus vermeintlicher Notwendigkeit genommen. Ein Modul greift direkt auf ein anderes Modul zu. Ein Bericht fragt Produktionstabellen auf eine Weise ab, die niemand so vorgesehen hat. Ein Workflow hängt von Daten aus einer Integration ab, die nie als Quelle der Wahrheit gedacht war. Ein Hintergrundjob aktualisiert stillschweigend einen Zustand, von dem ein anderer Teil des Systems annimmt, dass er ihn kontrolliert.
Jede Abkürzung löst ein unmittelbares Problem, schafft aber langfristig ein neues:Â Sie führt zu einem System, in dem niemand mehr vor Ort Entscheidungen treffen kann.
Bevor ein Bereich geändert wird, muss das Team prüfen, wer sonst noch davon abhängt. Bevor ein Dienst freigegeben wird, muss es mehrere voneinander unabhängige Abläufe koordinieren. Bevor ein Feld bereinigt wird, muss es feststellen, ob noch ein Bericht, Export, Skript oder eine Anbieterintegration es verwendet.
Hier beginnt die Lieferung auf eine Weise langsamer zu werden, die Planungstools nicht erklären oder identifizieren können.
Der Projektplan mag Aufgaben zeigen, die einzelnen Teams zugewiesen sind, doch die Architektur zwingt diese Teams zu einem ständigen Management wechselseitiger Abhängigkeiten. Jede Änderung wird zu einer kleinen politischen und technischen Verhandlung.
Auch ein Wildwuchs an Abhängigkeiten erschwert die Priorisierung.
Die Führung möchte bei einem geschäftskritischen Workflow vielleicht schnell vorankommen, aber das Team kann die Arbeit nicht isolieren. Eine scheinbar klar abgegrenzte Initiative zieht nicht zusammenhängende Systembereiche mit hinein, weil die Architektur zugelassen hat, dass Verantwortlichkeiten über Grenzen hinweg ausfransen.
Deshalb scheitert es oft, einfach mehr Leute hinzuzufügen.
Wenn das System zu stark verflochten ist, verursachen mehr Personen auch mehr Koordinationsaufwand. Das Problem ist nicht die Kapazität. Das Problem ist, dass die Architektur keine saubere Trennung der Arbeit ermöglicht.
Signal 4: Tests stützen sich zu sehr auf manuelle Überprüfung
Ein System, das sich nicht sauber testen lässt, kann nicht sicher verändert werden.
Das bedeutet nicht, dass jedes System eine perfekte automatisierte Test-Suite braucht. Das ist für viele Legacy- oder schnelllebige Umgebungen nicht realistisch. Die Führungsebene sollte sich jedoch Sorgen machen, wenn das Vertrauen in Releases hauptsächlich von manueller Prüfung, dem Gedächtnis der Entwickler oder einigen wenigen Personen abhängt, die „wissen, wo die riskanten Stellen sind.“
Das ist keine Qualitätsstrategie – das ist ein institutionelles Risiko.
Die Warnzeichen sind in der Regel leicht zu erkennen:
- Das Team vermeidet Refactoring, weil es nicht nachweisen kann, was dabei beschädigt wurde.
- Regressionstests dauern zu lange und übersehen dennoch wichtige Pfade.
- Produktionsfehler treten in Workflows auf, die angeblich nichts mit der Änderung zu tun hatten.
- Entwickler verlassen sich auf manuelle Datenbankprüfungen, um das Verhalten zu verifizieren.
- Testumgebungen bilden das Produktionsverhalten nicht genau genug ab.
- Wichtige Geschäftsregeln sind nicht durch zuverlässige Tests abgedeckt.
- Das Team sagt âÂÂwir haben das Feature getestet,â aber nicht âÂÂwir haben das betroffene Systemverhalten getestet.âÂÂ
Dies ist ein architektonisches Problem, da die Testbarkeit größtenteils eine Folge der Systemstruktur ist.
Wenn Geschäftslogik verstreut ist, hinter Seiteneffekten verborgen, eng an die Infrastruktur gekoppelt oder direkt mit Präsentations- und Integrationsschichten vermischt wird, wird das Testen teuer und anfällig für Fehler. Die Folge sind langsamere Auslieferungen und sinkendes Vertrauen.
Das erzeugt ebenfalls einen negativen Kreislauf.
Weil Testen schwierig ist, testet das Team weniger, als es sollte. Weil das Team weniger testet, werden Änderungen riskanter. Weil Änderungen riskant sind, werden Releases langsamer. Weil Releases langsamer werden, steigt der Druck. Weil der Druck steigt, werden Abkürzungen attraktiver.
Diese Schleife löst sich leider nicht von selbst.
Es erfordert ein bewusstes und gezieltes Eingreifen.
Das Ziel hier ist nicht, den Geschäftsbetrieb anzuhalten und eine perfekte Testarchitektur zu schaffen. Das ist in der Regel unrealistisch und oft sogar Verschwendung. Der bessere Ansatz ist, die geschäftlichen Abläufe mit dem höchsten Risiko zu identifizieren und zunächst die Testbarkeit dafür aufzubauen.
Praktisch bedeutet das, kritische Geschäftsregeln zu isolieren, verlässliche Regressionstests für umsatzrelevante Workflows aufzubauen, Umgebungen zu stabilisieren und die Release-Sicherheit weniger von heroischem manuellem Einsatz abhängig zu machen.
Signal 5: Die Verantwortlichkeiten auf Systemgrenzenebene sind unklar
Viele Organisationen glauben, sie hätten die Verantwortung, nur weil Aufgaben zugewiesen sind.
Das reicht jedoch nicht aus.
Die Verantwortung für Aufgaben ist nicht dasselbe wie die Verantwortung für das System.
Ein Entwickler kann ein Ticket besitzen. Ein Team kann ein Sprintziel besitzen. Ein Projektmanager kann einen Zeitplan besitzen. Aber wer ist für das Verhalten eines Workflows über mehrere Module hinweg verantwortlich? Wer ist für den API-Vertrag verantwortlich? Wer ist für die Datenkonsistenz zwischen Systemen verantwortlich? Wer ist für die betrieblichen Folgen nach dem Release verantwortlich? Wer trifft die Entscheidung, wenn zwei Teile der Architektur in Konflikt stehen?
Wenn die Antworten auf diese Fragen unklar sind, wird das Lieferungsrisiko weiter steigen.
Dieses Problem wird besonders in wachsenden Teams sichtbar. Anfangs kann eine kleine Gruppe das gesamte System im Kopf behalten. Entscheidungen werden informell getroffen. Jeder weiß, wen man fragen muss. Architektonische Grenzen können implizit bleiben.
Das bricht zusammen, sobald das System und das Team wachsen.
Neue Entwickler brauchen klare Zuständigkeiten. Anbieter brauchen klare Schnittstellen. Der Betrieb braucht klare Supportwege. Die Führung braucht klare Verantwortlichkeit. Ohne diese werden technische Entscheidungen unkoordiniert und reaktiv.
Das System beginnt sich je nachdem zu verändern, wer es zuletzt berührt hat, und die Verantwortung wird oft gleich mit zugewiesen.
Das ist keine Architektur. Das ist Ansammlung.
Unklare Verantwortlichkeiten führen auch zu Engpässen bei der Überprüfung. Wenn niemand eindeutig verantwortlich ist, erfordert jede wesentliche Änderung eine breite Abstimmung. Wenn zu viele Personen verantwortlich sind, hat niemand echte Entscheidungsbefugnis. Wenn eine einzelne erfahrene Person inoffiziell für alles zuständig ist, hat die Organisation einen Engpass geschaffen, der sich als Expertise tarnt.
Das Ergebnis ist vorhersehbar: langsamere Auslieferung, inkonsistente Entscheidungen, überlastete erfahrene Mitarbeitende und ein System, das von Quartal zu Quartal schwerer nachzuvollziehen ist.
Warum diese Signale oft übersehen werden
Diese Architektur-Signale sind leicht zu übersehen, weil keines von ihnen auf den ersten Blick dramatisch wirkt oder sie schlicht gar nicht erkannt werden.
Das Team liefert weiterhin. Das System funktioniert weiterhin. Kunden beschweren sich vielleicht noch nicht. Der Backlog wird weiterhin abgearbeitet. Die meisten Meetings klingen noch ganz normal.
Doch die Kosten des Wandels steigen und steigen.
Das ist der Punkt, den Führungskräfte verstehen müssen.
Das Risiko bei der architektonischen Bereitstellung wird nicht nur an Ausfällen oder fehlgeschlagenen Releases gemessen. Es bemisst sich auch daran, wie viel Aufwand erforderlich ist, um die nächste sinnvolle Änderung sicher auszuliefern.
Ein System kann heute betriebsbereit sein und dennoch strukturell nicht darauf vorbereitet sein, was das Unternehmen morgen von ihm erwartet.
Das ist auch der Punkt, an dem sich viele Unternehmen selbst etwas vormachen. Sie gehen davon aus, dass die Architektur in Ordnung ist, nur weil das System derzeit funktioniert, und dass die Pflege der Architektur rein optional ist. Das muss nicht unbedingt stimmen. Die bessere Frage ist, ob die Architektur die geschäftliche Ausrichtung noch unterstützt, und wer dafür sorgt, dass diese Ziele weiterhin aufeinander abgestimmt bleiben?
Kann das Team Funktionen hinzufügen, ohne übermäßige Nebenwirkungen zu verursachen?
Kann das System betriebliche Änderungen verarbeiten?
Können neue Entwickler produktiv werden, ohne auf Insiderwissen angewiesen zu sein?
Können Releases sicher ohne besondere Koordination stattfinden?
Kann das Unternehmen Entscheidungen treffen, ohne festzustellen, dass jede Option durch alte technische Kompromisse blockiert wird?
Wenn die Antwort auf eine dieser Fragen unklar ist, zahlt das Unternehmen möglicherweise bereits eine Architektursteuer. Sie wurde nur noch nicht benannt oder überhaupt erkannt.
Die Diagnose: normale Komplexität von architektonischem Risiko trennen
Nicht jedes Problem mit langsamer Auslieferung ist ein Architekturproblem.
Manche Systeme sind komplex, weil das Geschäft komplex ist. Manche Workflows erfordern tatsächlich eine sorgfältige Abstimmung. Manche Releases sind langsam, weil regulatorische, operative oder kundenseitige Vorgaben sie verlangsamen. Nicht alles sollte der Architektur angelastet werden.
Die entscheidende Frage ist, ob die Komplexität wesentlich oder zufällig bedingt ist.
Die wesentliche Komplexität ergibt sich aus der geschäftlichen Realität. Sie ist möglicherweise unvermeidlich.
Unbeabsichtigte Komplexität entsteht dadurch, wie das System gewachsen ist. Sie lässt sich oft reduzieren.
Eine nützliche architektonische Analyse sollte Fragen wie diese beantworten:
- Welche Geschäftskonzepte haben im Code oder im Systemdesign eine unklare Zuständigkeit?
- Welche Workflows erfordern Änderungen in zu vielen voneinander unabhängigen Bereichen?
- Welche Module, Services oder Integrationen haben Verträge, denen die Teams nicht vollständig vertrauen?
- Wo werden Geschäftsregeln doppelt gepflegt?
- Welche Abhängigkeiten machen Releases langsamer, als sie sein sollten?
- Welche Bereiche lassen sich nicht ohne übermäßigen manuellen Aufwand testen?
- Welche Teile des Systems stützen sich auf das Gedächtnis von ein oder zwei Personen?
- Welche jüngsten Fehler wurden durch unerwartete Seiteneffekte verursacht?
- Welche technischen Entscheidungen werden immer wieder neu aufgerollt, weil die Zuständigkeit unklar ist?
- Welche Systemgrenzen passen nicht mehr dazu, wie das Unternehmen arbeitet?
Der Zweck dieser Überprüfung besteht nicht darin, ein ansprechendes Architektur-Dokument zu erstellen.
Entscheidend ist, zu erkennen, wo die Architektur die Umsetzung derzeit einschränkt und wo gezielte Maßnahmen Geschwindigkeit, Sicherheit und Planbarkeit verbessern würden.
Die Maßnahme: Was zuerst behoben werden sollte
Die falsche Reaktion auf architektonische Risiken besteht darin, einen umfassenden Neuaufbau ohne vorherige Analyse anzukündigen. Das ist in der Regel ein teurer Weg, ein Risiko durch ein anderes zu ersetzen.
Eine bessere Intervention beginnt kleiner und gezielter.
Der erste Schritt besteht darin, die für die Auslieferung kritischen Abläufe zu identifizieren.
Nicht jeder Teil des Systems verdient die gleiche Aufmerksamkeit. Das Unternehmen sollte sich zunächst auf Workflows konzentrieren, die sich direkt auf Umsatz, Betrieb, Kundenerlebnis, Compliance oder Release-Stabilität auswirken. Das sind die Bereiche, in denen architektonische Trägheit die höchsten geschäftlichen Kosten verursacht.
Der zweite Schritt besteht darin, die Reibung bei Veränderungen zu erfassen.
Schauen Sie sich die jüngsten Arbeiten an. Welche Änderungen haben länger gedauert als erwartet? Welche haben Fehler verursacht? Welche erforderten zu viele Genehmigungen, zu viel Abstimmung oder zu viel Recherche? Welche Teile des Systems scheuen Entwickler davor, sie anzufassen?
Dieser Beleg ist nützlicher als eine abstrakte Debatte über Architektur.
Der dritte Schritt besteht darin, die Verantwortungsbereiche festzulegen.
Das bedeutet, festzulegen, welches Team, welches Modul, welcher Service oder welcher Anbieter welche Geschäftsfähigkeit, welchen Vertrag, welche Datenverantwortung und welches operative Verhalten verantwortet. Diese Grenzen sollten praxisnah sein. Sie müssen nicht theoretisch perfekt sein. Sie sollen Verwirrung verringern und Entscheidungen erleichtern.
Der vierte Schritt besteht darin, die riskantesten Verträge zu stabilisieren.
APIs, Events, gemeinsame Datenstrukturen, Integrationspunkte und interne Modulschnittstellen sollten dort explizit gemacht werden, wo sie am wichtigsten sind. Ein Vertrag muss nicht kompliziert sein, aber er muss zuverlässig genug sein, damit Teams darauf aufbauen können, ohne ständig nachfragen zu müssen.
Der fünfte Schritt besteht darin, die Testbarkeit kritischer Funktionen zu verbessern.
Beginnen Sie mit den Workflows, bei denen Fehler teuer sind. Bauen Sie eine Regressionstestabdeckung auf, isolieren Sie nach Möglichkeit Geschäftsregeln, verringern Sie die Abhängigkeit von manueller Validierung und machen Sie produktionsähnliches Verhalten vor dem Release leichter überprüfbar.
Der sechste Schritt besteht darin, die Abhängigkeitsverflechtung schrittweise zu reduzieren.
Dies kann bedeuten, Logik in klarere Module auszulagern, doppelte Regeln zu entfernen, Anti-Corruption-Layer um instabile Integrationen einzuführen oder sauberere Schnittstellen zwischen Teilen des Systems zu schaffen. Das Ziel ist nicht architektonische Reinheit. Das Ziel ist, künftige Änderungen weniger kostspielig zu machen.
Kompromisse und Risiken
Bei der Behebung von Risiken bei der architektonischen Umsetzung gibt es immer Kompromisse.
Der offensichtlichste Punkt ist, dass strukturelle Verbesserungen mit der Bereitstellung von Features konkurrieren. Einige Führungsteams sträuben sich dagegen, weil sie Architekturarbeit als interne Aufräumarbeit des Engineerings sehen.
Diese Sichtweise ist oft zu eng.
Wenn die aktuelle Struktur jede sinnvolle Veränderung ausbremst, dann ist Architekturarbeit nicht von der Umsetzung getrennt. Sie ist die Arbeit, die nötig ist, um die Lieferfähigkeit wiederherzustellen.
Das bedeutet jedoch nicht, dass jede Architekturverbesserung gerechtfertigt ist. Teams können leicht über das Ziel hinausschießen. Sie beginnen möglicherweise damit, Teile des Systems neu zu gestalten, die das Geschäft in Wirklichkeit gar nicht einschränken. Sie jagen vielleicht modischen Mustern hinterher. Sie schaffen möglicherweise Abstraktion um ihrer selbst willen. Sie machen aus einer praktischen Stabilisierungskampagne vielleicht ein Projekt technischer Ideologie.
Das ist Verschwendung.
Die Arbeit muss weiterhin an den Geschäftserfolg gekoppelt bleiben.
Ein weiterer Nachteil besteht darin, dass eine explizite Zuordnung von Verantwortlichkeiten unangenehme Lücken offenlegen kann. Manche Teams stellen vielleicht fest, dass sie von Systemen abhängen, für die niemand klar verantwortlich ist. Manche Anbieter arbeiten möglicherweise in Bereichen, in denen die interne Verantwortlichkeit schwach ausgeprägt ist. Manche Senior-Entwickler tragen womöglich zu viel verdeckte Verantwortung.
Das kann zu Reibungen führen, aber es ist eine nützliche Reibung.
Die Organisation wird nicht komplizierter. Sie erkennt endlich die Komplexität, die sie bereits mit sich getragen hat.
Architekturverbesserung bedeutet nicht, Diagramme sauberer zu machen. Es geht darum, Änderungen sicherer, schneller und leichter zu verantworten.
Es gibt auch ein Sequenzierungsrisiko. Wenn man versucht, zu viel auf einmal zu beheben, kann das die Umsetzung lähmen. Der bessere Ansatz ist eine kontrollierte Verbesserung: ein kritischer Workflow, eine Grenze, ein Vertrag, eine Testbarkeitslücke, ein Abhängigkeitsproblem nach dem anderen.
Architekturarbeit sollte den operativen Aufwand verringern und nicht selbst zu einer neuen Quelle werden.
Checkliste zur Umsetzung
Diese Checkliste kann Führungskräften und Engineering-Teams dabei helfen zu erkennen, ob architektonische Risiken beginnen, die Umsetzung zu beeinträchtigen:
- Überprüfen Sie die letzten fünf bis zehn verzögerten oder schwierigen Änderungen und identifizieren Sie wiederkehrende Reibungsmuster.
- Identifizieren Sie geschäftskritische Workflows, bei denen kleine Änderungen das Anpassen vieler Teile des Systems erfordern.
- Lokalisieren Sie doppelte Geschäftsregeln, insbesondere rund um Preise, Berechtigungen, Statusänderungen, operative Ausnahmen und Berichterstattung.
- Listen Sie Systemverträge auf, denen Teams nicht vollständig vertrauen oder die sie nicht vollständig verstehen.
- Identifizieren Sie Integrationen, Module oder Datenflüsse ohne klare Verantwortlichkeit.
- Erfassen Sie Abhängigkeiten, die Releases regelmäßig verlangsamen oder zusätzlichen Koordinationsaufwand verursachen.
- Finden Sie Bereiche, in denen die Release-Sicherheit stark von manuellen Tests oder individuellem Wissen abhängt.
- Identifizieren Sie Teile des Systems, die Entwickler vermeiden zu ändern.
- Überprüfen Sie Produktionsvorfälle und durchgerutschte Fehler auf architektonische Ursachen, nicht nur auf unmittelbare technische Ursachen.
- Definieren Sie die Verantwortlichkeiten für kritische Workflows, APIs, Datenzuständigkeiten und operative Übergaben.
- Stabilisieren Sie die Verträge, die die meisten Teams oder die risikoreichsten Workflows betreffen.
- Erstellen Sie automatisierte oder wiederholbare Regressionstests für umsatzrelevantes und betriebsrelevantes Verhalten.
- Vermeiden Sie umfassende Neuentwicklungen, es sei denn, die Analyse belegt eindeutig, dass Stabilisierung wirtschaftlich nicht mehr sinnvoll ist.
- Verfolgen Sie, ob Änderungen nach jeder Maßnahme einfacher, sicherer und vorhersehbarer werden.
Nützliche KPIs können die Änderungsdurchlaufzeit, durchgerutschte Fehler, die Häufigkeit von Release-Rollbacks, die Anzahl der pro Feature berührten Komponenten, die für Regressionstests aufgewendete Zeit, das Wiederauftreten von Incidents, durch Abhängigkeiten verursachte Blocker und das Alter von Entscheidungen im Zusammenhang mit der technischen Verantwortung umfassen.
Wie „gut“ nach der Stabilisierung aussieht
Nach den richtigen architektonischen Maßnahmen sollte die Bereitstellung weniger fragil wirken.
Das bedeutet nicht, dass das System perfekt wird. Es bedeutet, dass das Team wichtige Änderungen mit mehr Zuversicht und weniger unnötiger Abstimmung vornehmen kann.
Gute Architektur ist in diesem Kontext praxisnah und zeigt sich im Lieferverhalten.
Teams verstehen, wo die Geschäftsregeln verankert sind. Verträge sind explizit genug, um ihnen zu vertrauen. Kritische Workflows haben klare Verantwortliche. Das wichtigste Verhalten lässt sich testen, ohne sich vollständig auf manuelles Vertrauen zu verlassen. Neue Entwickler können das System schneller nachvollziehen. Releases erfordern weniger Heldentum. Technische Entscheidungen kreisen nicht mehr endlos, weil die Zuständigkeiten klarer sind.
Vor allem gewinnt die Führungsebene an besserer Planbarkeit.
Nicht, weil jede Schätzung perfekt wird, sondern weil das Team bei jeder wichtigen Änderung nicht mehr gegen versteckte strukturelle Bremsen ankämpfen muss.
Eine gesunde Architektur beseitigt Komplexität nicht. Sie hält sie in Grenzen.
Es ermöglicht dem Unternehmen, voranzukommen, ohne dass jede neue Anforderung wie eine riskante Auseinandersetzung mit der Vergangenheit wirkt.
Wenn sich Ihre Softwarebereitstellung verlangsamt und die üblichen Erklärungen nicht mehr greifen, liegt das Problem möglicherweise nicht am Backlog, am Sprint-Prozess oder am Einsatz des Teams.
Es könnte die eigentliche Systemstruktur darunter sein.
Binarika hilft Organisationen dabei, architektonische Risiken bei der Bereitstellung zu diagnostizieren, Verantwortungsgrenzen zu stabilisieren, Reibungen durch Abhängigkeiten zu reduzieren und sicherere Bereitstellungsmuster wiederherzustellen, ohne vorschnell auf unnötige Neuaufbauten zu setzen. Eine gezielte Architektur- und Delivery-Analyse kann oft klären, ob der richtige nächste Schritt Stabilisierung, Modernisierung oder ein tieferer struktureller Neustart ist.