Problemen met softwarelevering ontstaan zelden plotseling.
Tegen de tijd dat een project duidelijk te maken heeft met terugkerende vertragingen, zijn de zichtbare symptomen meestal al een tijdje aanwezig. Sprintdoelen worden steeds weer niet gehaald. Schattingen worden steeds minder betrouwbaar. Eenvoudige wijzigingen kosten meer tijd dan verwacht. Het team is voorzichtiger gaan werken. Er duiken meer defecten op in onderdelen die eigenlijk al stabiel zouden moeten zijn, als gevolg van wijzigingen in andere delen. Releases vragen meer coördinatie dan zou moeten.
Van buitenaf of op het eerste gezicht kan dit sterk lijken op een bezorgprobleem.
Het management kan zich afvragen waarom het team niet sneller vooruitgaat, waarom de schattingen niet kloppen, waarom ontwikkelaars steeds aan dezelfde onderdelen van het systeem moeten werken, of waarom elke nieuwe functie onverwachte neveneffecten lijkt te veroorzaken.
Dat zijn natuurlijk terechte vragen, maar ze richten zich vaak op de verkeerde laag.
In veel gevallen wordt het leveringsprobleem niet in de eerste plaats veroorzaakt door een gebrek aan inzet, zwakke ontwikkelaars of slecht taakbeheer. De echte beperking is vaak van architectonische aard. Het systeem heeft een punt bereikt waarop de structuur niet langer de snelheid, veiligheid of duidelijkheid ondersteunt die het bedrijf ervan verwacht.
Dit is een lastige fase, omdat het project nog steeds erg actief kan lijken. Er wordt gewerkt. Pull requests worden samengevoegd. Er vinden vergaderingen plaats. De backlog schuift op. Maar onder al die activiteit blijft de prijs van al deze veranderingen alleen maar stijgen.
Het team bouwt niet langer simpelweg functies; het moet voortdurend onderhandelen met de architectuur en ertegen vechten.
Wanneer de architectuur levering niet langer ondersteunt, wordt elke wijziging duurder dan het lijkt.
Deze situatie is belangrijk voor CEO’s, CTO’s, engineeringmanagers en projectleiders, omdat problemen bij de oplevering van architectuur niet lang technisch blijven. Ze leiden al snel tot gemiste afspraken, een trage reactie op marktbehoeften, terugkerende kwetsbare releases, een groeiend aantal incidenten, gefrustreerde teams en uiteindelijk het onnodige afnemende vertrouwen tussen business en engineering.
Hoe eerder deze signalen worden herkend, hoe gemakkelijker ze te corrigeren zijn.
De veelvoorkomende misvatting over architectuur
Architectuur wordt vaak te abstract besproken.
Het wordt gezien als een technische voorkeur, een optionele stap in de ontwikkeling, een diagram, een keuze voor een framework of iets waar senior engineers over discussiëren terwijl de business wacht op oplevering. Dat is niet de juiste manier om ernaar te kijken, en bedrijven die dat wel doen, stellen zichzelf bloot aan onnodige risico's en falen.
Architectuur in software legt een operationele beperking vast, vergelijkbaar met hoe de architectuur van een echt gebouw bepaalt wat er mogelijk is met het gebouw en hoe gemakkelijk het is om er veranderingen in aan te brengen.
Softwarearchitectuur bepaalt hoe gemakkelijk een team wijzigingen kan doorvoeren, risico's kan afschermen, gedrag kan testen, nieuwe ontwikkelaars kan inwerken, kan integreren met andere systemen en kan herstellen van fouten. Goede architectuur betekent niet dat het systeem elegant is volgens een of andere theoretische norm. Het betekent dat het systeem het bedrijf in staat stelt om te blijven veranderen, zonder dat elke wijziging buitensporig risicovol of traag wordt, of onderdelen van de software beïnvloedt die daar niet bij betrokken zouden moeten zijn.
Slechte softwarearchitectuur is niet altijd zo zichtbaar als slechte code.
Soms is de code op zichzelf volkomen begrijpelijk en werkt die prima. Het probleem zit in de structuur van het systeem: onduidelijke grenzen, verborgen afhankelijkheden, gedupliceerde bedrijfsregels, onbetrouwbare contracten en hiaten in eigenaarschap tussen modules, teams of leveranciers.
Daarom worden architectuurproblemen zo vaak onderschat of zelfs niet eens herkend.
Een enkele vertraging van een functie lijkt misschien een lokaal leveringsprobleem. Maar wanneer elke vertraging van een functie hetzelfde patroon heeft, is het probleem niet langer lokaal. Het systeem geeft je deze informatie eigenlijk gewoon.
Leiderschap moet hier aandacht aan besteden voordat de organisatie met de verkeerde interventie reageert.
- Meer druk uitoefenen zal onduidelijke grenzen niet oplossen.
- Meer ontwikkelaars toevoegen kan de wildgroei aan afhankelijkheden verergeren.
- Meer projectmanagement toevoegen zal niet compenseren voor contracten die niemand vertrouwt.
- Meer QA aan het einde toevoegen zal problemen met een systeem dat niet goed getest kan worden niet oplossen.
De juiste ingreep begint met het vroegtijdig herkennen van de architectonische signalen.
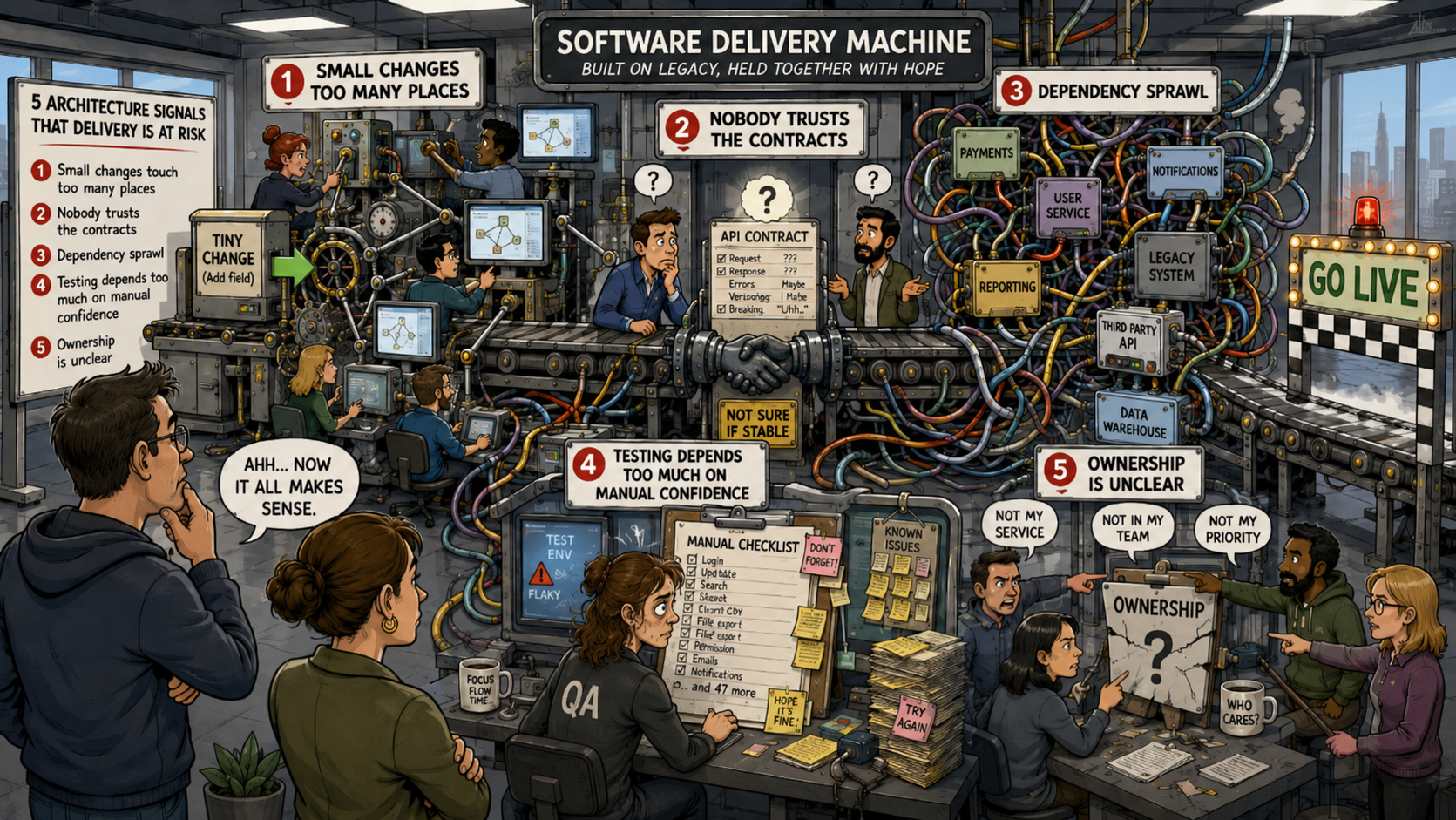
Signaal 1: Kleine wijzigingen vereisen aanpassingen op te veel plekken
Een van de duidelijkste signalen van leveringsproblemen is wanneer kleine bedrijfswijzigingen aanpassingen vereisen in te veel onderdelen van het systeem.
Een prijsregel wijzigt, maar dat heeft invloed op offertes, facturen, rapporten, machtigingen, meldingen en verschillende achtergrondtaken.
De status van een klant verandert, maar het team moet vijf verschillende plekken controleren waar de statuslogica gedeeltelijk is gedupliceerd.
Er wordt een nieuwe operationele uitzondering ingevoerd, maar niemand weet precies welke workflows hierdoor worden beïnvloed.
Dit is meer dan alleen ongemak. Het betekent dat het systeem geen duidelijke eigenaar heeft van zijn bedrijfsconcepten.
Wanneer een wijziging zich te breed verspreidt, moet het team tijd besteden aan het opsporen van elk getroffen gebied, het doorgronden van neveneffecten, het coördineren van reviews, het bijwerken van tests en het handmatig valideren van gedrag. De levering vertraagt omdat elke wijziging verborgen onderzoekswerk met zich meebrengt, en inschattingen worden onnauwkeurig door de toenemende moeilijkheid om dit verborgen werk te voorspellen.
De zichtbare taak lijkt misschien klein - het daadwerkelijke veranderingsgebied is groot.
Dit wijst meestal op zwakke domeingrenzen. Het systeem is mogelijk organisch gegroeid, waarbij bedrijfslogica werd toegevoegd waar dat op dat moment het handigst was. In de beginfase was dat misschien acceptabel, maar naarmate het bedrijf groeit, wordt gemak een vorm van koppeling.
Het risico hier is niet alleen tragere levering. Het echte risico is dat het team uiteindelijk veranderingen gaat vermijden.
Ze worden op de verkeerde manier voorzichtig, omdat ze wel moeten. Ze stellen verbeteringen uit omdat ze de neveneffecten niet kunnen voorspellen. Ze voegen patches toe in plaats van de structuur te herstellen. Ze houden slechte processen in stand omdat eraan sleutelen te gevaarlijk voelt.
Zo wordt technische schuld operationele schuld.
Signaal 2: Niemand vertrouwt de contracten tussen de onderdelen van het systeem
Een gezond systeem heeft grenzen en verantwoordelijkheden waarop teams kunnen vertrouwen.
Een module, service, API, integratie of intern proces moet een duidelijk contract hebben: wat het verwacht, wat het teruggeeft, wat fouten betekenen, wie eigenaar is en op welk gedrag andere onderdelen van het systeem kunnen vertrouwen.
Wanneer die contracten onduidelijk of instabiel zijn, wordt levering een onderhandelingsproces.
Ontwikkelaars moeten de daadwerkelijke implementatiedetails inspecteren in plaats van te vertrouwen op gedocumenteerd gedrag. Teams vragen elkaar of een veld altijd aanwezig is, waarom sommige velden soms optioneel zijn en soms verplicht, of een status kan worden overgeslagen, of een integratie automatisch opnieuw probeert, of een fout betekent dat iets is mislukt of vertraagd, en of een endpoint veilig kan worden aangeroepen tijdens piekuren.
Dit maakt elke wijziging alleen maar omslachtiger.
Het creëert ook een gevaarlijke vorm van onzekerheid: het systeem werkt misschien meestal, maar niemand kan met vertrouwen uitleggen waarom het werkt, onder welke omstandigheden het zeker zal werken, wanneer het faalt of waarop een ander team mag vertrouwen.
Dat is een zeer ernstig leveringsrisico.
Onduidelijke contracten zijn vooral schadelijk in systemen waarbij meerdere teams, leveranciers, operationele workflows of klantgerichte processen betrokken zijn. Elk onduidelijk contract vormt een coördinatielast. Elke ongedocumenteerde aanname kan uitmonden in een incident. Elke mislukking leidt tot afnemend vertrouwen en toenemende wrijving tussen teams.
De werkelijke bedrijfskosten worden zichtbaar tijdens integratie, UAT, productiereleases, onboarding en incidentafhandeling.
Een team kan onduidelijke contracten een tijdlang compenseren met ervaring en informele communicatie. Maar dat schaalt niet. Zodra sleutelpersonen niet beschikbaar zijn, nieuwe ontwikkelaars aansluiten, leveranciers veranderen of het systeem uitbreidt, verandert verborgen kennis in instabiliteit in de oplevering.
Als het team eerst rond moet vragen voordat het iets belangrijks verandert, draagt de architectuur niet genoeg kennis over.
Signaal 3: Wildgroei aan afhankelijkheden vertraagt elke beslissing
Afhankelijkheidswildgroei ontstaat wanneer te veel onderdelen van het systeem afhankelijk zijn van te veel andere onderdelen, zonder duidelijke reden, hiërarchie of eigenaarsmodel.
Dit kan gebeuren binnen de codebase, tussen services, tussen teams of tussen bedrijfsprocessen.
In eerste instantie lijkt het misschien niet zo ernstig. Er worden een paar shortcuts genomen uit wat op het eerste gezicht noodzaak lijkt. Een module grijpt rechtstreeks in een andere module. Een rapport bevraagt productietabellen op een manier die niemand had bedoeld. Een workflow is afhankelijk van gegevens uit een integratie die nooit als bron van waarheid was ontworpen. Een achtergrondtaak werkt stilletjes status bij waarvan een ander deel van het systeem aanneemt dat het die beheert.
Elke shortcut lost een direct probleem op, maar creëert op de lange termijn een nieuw probleem:Â ze creëren een systeem waarin niemand meer lokaal beslissingen kan nemen.
Voordat ze één onderdeel wijzigen, moet het team controleren wie er nog meer van afhankelijk is. Voordat ze één service vrijgeven, moeten ze afstemmen met verschillende losstaande processen. Voordat ze een veld opschonen, moeten ze bepalen of een rapport, export, script of integratie met een leverancier het nog steeds gebruikt.
Hier begint de levering op een manier trager te worden die planningshulpmiddelen niet kunnen verklaren of vaststellen.
Het projectplan kan taken tonen die aan afzonderlijke teams zijn toegewezen, maar de architectuur dwingt die teams tot voortdurend beheer van onderlinge afhankelijkheden. Elke wijziging wordt een kleine politieke en technische onderhandeling.
Afhankelijkheidswildgroei maakt prioriteren ook moeilijker.
Het management wil misschien snel schakelen bij een bedrijfskritische workflow, maar het team kan het werk niet isoleren. Een ogenschijnlijk afgebakend initiatief trekt onverwacht ook niet-gerelateerde systeemonderdelen mee, omdat de architectuur heeft toegestaan dat verantwoordelijkheden over grenzen heen zijn gaan lekken.
Daarom werkt het vaak niet om meer mensen toe te voegen.
Als het systeem te verstrengeld is, zorgen meer mensen voor meer coördinatie-overhead. Het probleem is niet de capaciteit. Het probleem is dat de architectuur het niet mogelijk maakt om werk duidelijk van elkaar te scheiden.
Signaal 4: Testen leunt te veel op handmatig vertrouwen
Een systeem dat niet goed getest kan worden, kan niet veilig worden aangepast.
Dit betekent niet dat elk systeem een perfecte geautomatiseerde testsuite nodig heeft. Dat is voor veel legacy- of snel veranderende omgevingen niet realistisch. Maar het management zou zich zorgen moeten maken wanneer het vertrouwen in een release vooral afhangt van handmatige controle, het geheugen van ontwikkelaars of een paar mensen die âÂÂweten waar de risicovolle onderdelen zitten.âÂÂ
Dat is geen kwaliteitsstrategie - dat is een institutioneel risico.
De waarschuwingssignalen zijn meestal gemakkelijk te herkennen:
- Het team vermijdt refactoring omdat ze niet kunnen aantonen wat ze hebben stukgemaakt.
- Regressietests duren te lang en missen nog steeds belangrijke paden.
- Productiefouten duiken op in workflows die zogenaamd niets met de wijziging te maken hadden.
- Ontwikkelaars vertrouwen op handmatige databasecontroles om het gedrag te verifiëren.
- Testomgevingen weerspiegelen het gedrag in productie niet nauwkeurig genoeg.
- Kritieke bedrijfsregels worden niet afgedekt door betrouwbare tests.
- Het team zegt âÂÂwe tested the feature,â maar niet âÂÂwe tested the affected system behavior.âÂÂ
Dit is een architectuurprobleem, omdat testbaarheid grotendeels voortkomt uit de systeemstructuur.
Als bedrijfslogica verspreid is, verborgen achter neveneffecten, nauw verweven met de infrastructuur of rechtstreeks vermengd met presentatie- en integratielagen, wordt testen duur en kwetsbaar. Het resultaat is tragere levering en afnemend vertrouwen.
Dit zorgt ook voor een negatieve spiraal.
Omdat testen moeilijk is, test het team minder dan zou moeten. Omdat het team minder test, worden wijzigingen risicovoller. Omdat wijzigingen risicovol zijn, verlopen releases trager. Omdat releases trager zijn, neemt de druk toe. Omdat de druk toeneemt, worden shortcuts aantrekkelijker.
Die lus lost zichzelf helaas niet vanzelf op.
Het vereist een doelgerichte en weloverwogen ingreep.
Het doel hier is niet om de business stil te leggen en een perfecte testarchitectuur te creëren. Dat is meestal onrealistisch en vaker wel dan niet zelfs verspilling. De betere aanpak is om de bedrijfsprocessen met het hoogste risico te identificeren en daar eerst testbaarheid voor te ontwikkelen.
In de praktijk betekent dat het isoleren van kritieke bedrijfsregels, het opzetten van betrouwbare regressiedekking voor workflows die van invloed zijn op de omzet, het stabiliseren van omgevingen en het verminderen van de afhankelijkheid van releasevertrouwen van heroïsche handmatige inspanningen.
Signaal 5: Eigenaarschap is onduidelijk op systeemgrensniveau
Veel organisaties denken dat ze eigenaarschap hebben omdat taken zijn toegewezen.
Dat is echter niet genoeg.
Taakeigenaarschap is niet hetzelfde als systeemeigenaarschap.
Een ontwikkelaar kan eigenaar zijn van een ticket. Een team kan eigenaar zijn van een sprintdoel. Een projectmanager kan eigenaar zijn van een planning. Maar wie is eigenaar van het gedrag van een workflow over meerdere modules heen? Wie is eigenaar van het API-contract? Wie is eigenaar van de dataconsistentie tussen systemen? Wie is eigenaar van de operationele gevolgen na de release? Wie neemt de beslissing wanneer twee onderdelen van de architectuur met elkaar in conflict zijn?
Als de antwoorden op deze vragen onduidelijk zijn, zal het leveringsrisico blijven toenemen.
Dit probleem wordt vooral zichtbaar in groeiende teams. In het begin kan een kleine groep het hele systeem nog in het hoofd houden. Beslissingen worden informeel genomen. Iedereen weet wie je moet vragen. Architecturale grenzen kunnen impliciet blijven.
Dat valt al snel uit elkaar zodra het systeem en het team groeien.
Nieuwe ontwikkelaars hebben duidelijke eigenaarschap nodig. Leveranciers hebben duidelijke interfaces nodig. Operations heeft duidelijke ondersteuningspaden nodig. Leidinggevenden hebben duidelijke verantwoordelijkheid nodig. Zonder dat worden technische beslissingen versnipperd en reactief.
Het systeem begint te veranderen op basis van wie het het laatst aanraakt, en de verantwoordelijkheid wordt vaak meteen mee toegewezen.
Dat is geen architectuur. Dat is een opstapeling.
Onduidelijk eigenaarschap zorgt ook voor knelpunten in reviews. Als niemand duidelijk verantwoordelijk is, vereist elke betekenisvolle wijziging brede afstemming. Als te veel mensen verantwoordelijk zijn, heeft niemand echte beslissingsbevoegdheid. Als één senior persoon informeel overal eigenaar van is, heeft de organisatie een knelpunt gecreëerd dat vermomd is als expertise.
Het resultaat is voorspelbaar: tragere oplevering, inconsistente beslissingen, overbelaste senior medewerkers en een systeem dat elk kwartaal moeilijker te doorgronden wordt.
Waarom deze signalen vaak worden gemist
Deze architectuursignalen zijn gemakkelijk over het hoofd te zien, omdat geen ervan in eerste instantie dramatisch lijkt, of ze worden simpelweg helemaal niet herkend.
Het team levert nog steeds. Het systeem werkt nog steeds. Klanten klagen misschien nog niet. De backlog blijft nog steeds in beweging. De meeste vergaderingen klinken nog steeds normaal.
Maar de kosten van verandering nemen toe, en blijven toenemen.
Dat is wat leiderschap moet begrijpen.
Architectonisch leveringsrisico wordt niet alleen gemeten aan storingen of mislukte releases. Het wordt ook gemeten aan hoeveel inspanning nodig is om de volgende betekenisvolle wijziging veilig te kunnen opleveren.
Een systeem kan vandaag operationeel zijn en toch structureel niet voorbereid zijn op wat het bedrijf er morgen van verwacht.
Dit is ook het punt waarop veel bedrijven zichzelf voor de gek houden. Ze gaan ervan uit dat, omdat het systeem momenteel werkt, de architectuur acceptabel is en het onderhouden van de architectuur puur optioneel is. Dat is niet per se waar. De betere vraag is of de architectuur de bedrijfsrichting nog steeds ondersteunt, en wie ervoor zorgt dat die doelstellingen op één lijn blijven?
Kan het team functies toevoegen zonder buitensporige neveneffecten?
Kan het systeem operationele veranderingen verwerken?
Kunnen nieuwe ontwikkelaars productief worden zonder afhankelijk te zijn van impliciete kennis?
Kunnen releases veilig plaatsvinden zonder uitzonderlijke coördinatie?
Kan het bedrijf beslissingen nemen zonder te ontdekken dat elke optie wordt geblokkeerd door verouderde technische compromissen?
Als het antwoord op een van deze vragen vaag is, betaalt de organisatie mogelijk al een architecturale belasting. Die is alleen nog niet benoemd, of zelfs maar onderkend.
De diagnose: normale complexiteit scheiden van architectonisch risico
Niet elk probleem met trage levering is een architectuurprobleem.
Sommige systemen zijn complex omdat het bedrijf complex is. Sommige workflows vereisen nu eenmaal zorgvuldige afstemming. Sommige releases verlopen traag omdat regelgeving, operationele beperkingen of klantbeperkingen ze traag maken. Architectuur mag niet overal de schuld van krijgen.
De diagnostische vraag is of de complexiteit wezenlijk of toevallig is.
Essentiële complexiteit komt voort uit de zakelijke realiteit. Die kan onvermijdelijk zijn.
Onbedoelde complexiteit ontstaat door de manier waarop het systeem heeft kunnen groeien. Die kan vaak worden teruggebracht.
Een nuttige architecturale diagnose moet vragen beantwoorden zoals:
- Welke businessconcepten hebben onduidelijk eigenaarschap in de code of het systeemontwerp?
- Welke workflows vereisen wijzigingen in te veel niet-gerelateerde onderdelen?
- Welke modules, services of integraties hebben contracten die teams niet volledig vertrouwen?
- Waar worden businessregels gedupliceerd?
- Welke afhankelijkheden maken releases trager dan zou moeten?
- Welke onderdelen kunnen niet worden getest zonder buitensporig veel handmatige inspanning?
- Welke delen van het systeem zijn afhankelijk van het geheugen van één of twee personen?
- Welke recente defecten werden veroorzaakt door onverwachte neveneffecten?
- Welke technische beslissingen worden steeds opnieuw geopend omdat het eigenaarschap onduidelijk is?
- Welke systeemgrenzen komen niet langer overeen met hoe het bedrijf opereert?
Het doel van deze review is niet om een mooi architectuurdocument te produceren.
Het doel is vast te stellen waar de architectuur de levering momenteel belemmert en waar gerichte ingrepen de snelheid, veiligheid en voorspelbaarheid zouden verbeteren.
De ingreep: wat eerst aan te pakken
De verkeerde reactie op architectonisch risico is om een grote herbouw aan te kondigen zonder eerst een diagnose te stellen. Dat is meestal een dure manier om het ene risico te vervangen door een ander.
Een betere interventie begint kleinschaliger en doelgerichter.
De eerste stap is het identificeren van de voor de levering kritieke stromen.
Niet elk onderdeel van het systeem verdient evenveel aandacht. Het bedrijf moet zich eerst richten op workflows die direct van invloed zijn op omzet, bedrijfsvoering, klantervaring, compliance of release-stabiliteit. Dit zijn de gebieden waar architecturale vertraging de hoogste zakelijke kosten veroorzaakt.
De tweede stap is om de weerstand tegen verandering in kaart te brengen.
Kijk naar recent werk. Welke wijzigingen duurden langer dan verwacht? Welke veroorzaakten defecten? Welke vereisten te veel goedkeuringen, te veel afstemming of te veel onderzoek? Welke onderdelen van het systeem durven ontwikkelaars niet aan te raken?
Dat bewijs is nuttiger dan een abstract debat over architectuur.
De derde stap is het afbakenen van eigendomsgrenzen.
Dit betekent dat je bepaalt welk team, welke module, service of leverancier welke businesscapability, welk contract, welke gegevensverantwoordelijkheid en welk operationeel gedrag beheert. Deze grenzen moeten praktisch zijn. Ze hoeven niet theoretisch perfect te zijn. Ze moeten verwarring verminderen en het nemen van beslissingen makkelijker maken.
De vierde stap is om de meest risicovolle contracten te stabiliseren.
API's, events, gedeelde datastructuren, integratiepunten en interne module-interfaces moeten expliciet worden vastgelegd waar dat het het belangrijkst is. Een contract hoeft niet ingewikkeld te zijn, maar moet wel betrouwbaar genoeg zijn zodat teams erop kunnen bouwen zonder voortdurend om verduidelijking te hoeven vragen.
De vijfde stap is om de testbaarheid van kritieke functionaliteit te verbeteren.
Begin met de workflows waarbij falen kostbaar is. Bouw regressiedekking op, isoleer waar mogelijk de bedrijfsregels, verminder de afhankelijkheid van handmatige validatie en maak productieachtig gedrag eenvoudiger te verifiëren vóór de release.
De zesde stap is om de wildgroei aan afhankelijkheden geleidelijk te verminderen.
Dit kan inhouden dat logica wordt ondergebracht in duidelijkere modules, dubbele regels worden verwijderd, anti-corruptielagen worden geïntroduceerd rond instabiele integraties, of dat er duidelijkere interfaces worden gecreëerd tussen onderdelen van het systeem. Het doel is niet architectonische zuiverheid. Het doel is om toekomstige veranderingen minder kostbaar te maken.
Afwegingen en risico's
Er zijn altijd afwegingen bij het aanpakken van architectonische leveringsrisico's.
De meest voor de hand liggende is dat structurele verbetering concurreert met het opleveren van functionaliteit. Sommige leiderschapsteams verzetten zich hiertegen omdat ze architectuurwerk zien als interne opschoonwerkzaamheden binnen engineering.
Dat standpunt is vaak te beperkt.
Als de huidige structuur elke betekenisvolle verandering vertraagt, staat architectuurwerk niet los van de uitvoering. Het is werk dat nodig is om de levercapaciteit te herstellen.
Dat betekent echter niet dat elke architectuurverbetering gerechtvaardigd is. Teams kunnen gemakkelijk doorslaan. Ze kunnen beginnen met het herontwerpen van onderdelen van het systeem die het bedrijf in feite niet beperken. Ze kunnen modieuze patronen najagen. Ze kunnen abstractie om de abstractie zelf creëren. Ze kunnen van een praktische stabilisatie-inspanning een technisch ideologieproject maken.
Dat is zonde.
Het werk moet gekoppeld blijven aan zakelijke impact.
Een ander nadeel is dat het expliciet maken van eigenaarschap ongemakkelijke hiaten kan blootleggen. Sommige teams ontdekken misschien dat ze afhankelijk zijn van systemen waar niemand duidelijk eigenaar van is. Sommige leveranciers werken mogelijk in gebieden waar de interne verantwoordelijkheid zwak is. Sommige senior developers dragen misschien te veel verborgen verantwoordelijkheid.
Dit kan wrijving veroorzaken, maar het is nuttige wrijving.
De organisatie wordt niet ingewikkelder. Ze ziet eindelijk de complexiteit die ze al met zich meedroeg.
Architectuurverbetering gaat niet over het netter maken van diagrammen. Het gaat erom veranderingen veiliger, sneller en makkelijker te maken om te beheren.
Er is ook een risico in de volgorde. Te veel tegelijk proberen op te lossen kan de oplevering lamleggen. De betere aanpak is gecontroleerde verbetering: één kritieke workflow, één grens, één contract, één testbaarheidsprobleem, één afhankelijkheidsprobleem tegelijk.
Architectuurwerk moet operationele belasting verminderen, niet zelf een nieuwe bron daarvan worden.
Checklist voor implementatie
Deze checklist kan leiderschaps- en engineeringteams helpen vast te stellen of architectonisch risico de levering begint te beïnvloeden:
- Bekijk de laatste vijf tot tien vertraagde of lastige wijzigingen en identificeer terugkerende frictiepatronen.
- Breng bedrijfskritische workflows in kaart waarbij kleine wijzigingen vereisen dat veel onderdelen van het systeem worden aangepast.
- Zoek naar gedupliceerde bedrijfsregels, vooral rond prijsstelling, rechten, statuswijzigingen, operationele uitzonderingen en rapportage.
- Maak een lijst van systeemcontracten die teams niet volledig vertrouwen of begrijpen.
- Identificeer integraties, modules of datastromen zonder duidelijke eigenaar.
- Breng afhankelijkheden in kaart die releases regelmatig vertragen of extra coördinatie vergen.
- Zoek gebieden waar het vertrouwen in releases sterk afhangt van handmatige tests of individuele kennis.
- Identificeer onderdelen van het systeem die ontwikkelaars vermijden om aan te passen.
- Bekijk productie-incidenten en ontsnapte defects op architecturale oorzaken, niet alleen op directe technische oorzaken.
- Definieer eigenaarschap voor kritieke workflows, API's, data-verantwoordelijkheden en operationele overdrachten.
- Stabiliseer de contracten die de meeste teams of de workflows met het hoogste risico beïnvloeden.
- Bouw geautomatiseerde of herhaalbare regressiecontroles rond gedrag dat impact heeft op omzet en cruciaal is voor de operatie.
- Vermijd brede herschrijvingen, tenzij uit de diagnose duidelijk blijkt dat stabilisatie economisch niet langer zinvol is.
- Volg of wijzigingen na elke ingreep eenvoudiger, veiliger en voorspelbaarder worden.
Nuttige KPI’s kunnen onder meer zijn: doorlooptijd van wijzigingen, ontsnapte defecten, frequentie van release-rollbacks, aantal componenten dat per feature wordt aangepast, tijd besteed aan regressietesten, terugkerende incidenten, blokkades door afhankelijkheden en veroudering van beslissingen rond technisch eigenaarschap.
Hoe 'goed' eruitziet na stabilisatie
Na de juiste architecturale ingrepen zou de oplevering minder kwetsbaar moeten aanvoelen.
Dat betekent niet dat het systeem perfect wordt. Het betekent dat het team belangrijke wijzigingen met meer vertrouwen en minder onnodige afstemming kan doorvoeren.
Goede architectuur is in deze context praktisch en zichtbaar in het oplevergedrag.
Teams begrijpen waar de bedrijfsregels zich bevinden. Contracten zijn expliciet genoeg om op te vertrouwen. Kritieke workflows hebben duidelijke eigenaren. Het belangrijkste gedrag kan worden getest zonder volledig te vertrouwen op handmatige controle. Nieuwe ontwikkelaars kunnen sneller redeneren over het systeem. Releases vragen minder heldhaftigheid. Technische beslissingen blijven niet eindeloos rondgaan, omdat het eigenaarschap duidelijker is.
Het belangrijkste is dat leiderschap voorspelbaarder wordt.
Niet omdat elke inschatting perfect wordt, maar omdat het team niet langer bij elke betekenisvolle wijziging hoeft te vechten tegen verborgen structurele tegenwind.
Een gezonde architectuur elimineert complexiteit niet. Ze houdt die in toom.
Het stelt het bedrijf in staat om door te blijven gaan, zonder dat elke nieuwe vereiste voelt als een gevaarlijke onderhandeling met het verleden.
Als je softwarelevering vertraagt en de gebruikelijke verklaringen niet meer opgaan, ligt het probleem misschien niet bij de backlog, het sprintproces of de inzet van het team.
Het kan juist de systeemstructuur eronder zijn.
Binarika helpt organisaties architectonische leveringsrisico’s te diagnosticeren, eigendomsgrenzen te stabiliseren, afhankelijkheidsfrictie te verminderen en veiligere leveringspatronen te herstellen zonder terug te vallen op onnodige herbouw. Een gerichte architectuur- en leveringsreview kan vaak verduidelijken of de juiste volgende stap stabilisatie, modernisering of een diepere structurele herziening is.