Software delivery issues rarely appear suddenly.
By the time a project is clearly facing regular delays, the visible symptoms have usually been present for a while already. Sprint goals started and keep slipping. Estimates become less and less reliable. Simple changes are taking longer than expected. The team started to become more cautious. More defects started to appear in areas that should already be stable as an effect by changes in other areas. Releases require more coordination than they should.
From the outside or at first glance, this can look very much like a delivery problem.
Leadership may start asking why the team is not moving faster, why estimates are inaccurate, why developers keep touching the same parts of the system, or why every new feature seems to create unexpected side effects.
Those are fair questions to ask of course, but they are often aimed at the wrong layer.
In many cases, the delivery issue is not primarily caused by lack of effort, weak developers, or poor task management. The real constraint is often architectural in nature. The system has reached a point where its structure no longer supports the pace, safety, or clarity the business expects from it.
This is a tricky stage because the project may still look very active. Work is being done. Pull requests are being merged. Meetings are happening. The backlog is moving. But underneath all that activity, the cost of all this change only keeps increasing.
The team is not simply building features anymore; they are constantly negotiating with and having to fight the architecture.
When the architecture stops supporting delivery, every change becomes more expensive than it looks.
This situation matters for CEOs, CTOs, engineering managers, and project leaders because architectural delivery issues do not stay technical for long. They will become missed commitments, a slow response to market needs, recurring fragile releases, a growing incident volume, frustrated teams, and eventually the unnecessary declining trust between business and engineering.
The earlier these signals are being recognized, the easier they are to correct.
The common misunderstanding about architecture
Architecture is often discussed in a too abstract form.
It gets treated as a technical preference, an optional step in the development, a diagram, a framework choice, or something senior engineers debate while the business waits for delivery. That is not the right way to think about it and businesses that do, expose themselves to unnecessary risks and failure.
Architecture in software defines an operating constraint, similar to how real building architecture defines the constraint on what is possible to do with the building and how easy it is to make change to it.
Software architecture determines how easily a team can make changes, isolate risk, test behavior, onboard developers, integrate with other systems, and recover from mistakes. Good architecture does not mean the system is elegant according to some theoretical standard. It means the system allows the business to keep changing without every change becoming disproportionately risky or slow or affecting parts of the software that should not be involved.
Bad software architecture is not always as visible as bad code.
Sometimes the code is perfectly understandable and functioning right in isolation. The problem is in the shape of the system: unclear boundaries, hidden dependencies, duplicated business rules, unreliable contracts, and ownership gaps between modules, teams, or vendors.
This is why architecture problems are so often underestimated or even go unrecognized.
A single feature delay may look like a local delivery issue. But when every feature delay has the same pattern, the problem is no longer local. The system is actually providing you with this information.
Leadership should pay attention to this before the organization responds with the wrong intervention.
- Adding pressure will not fix unclear boundaries.
- Adding more developers may make dependency sprawl worse.
- Adding more project management will not compensate for contracts that nobody trusts.
- Adding more QA at the end will not solve problems with a system that cannot be tested cleanly.
The right intervention starts with recognizing the architectural signals early.
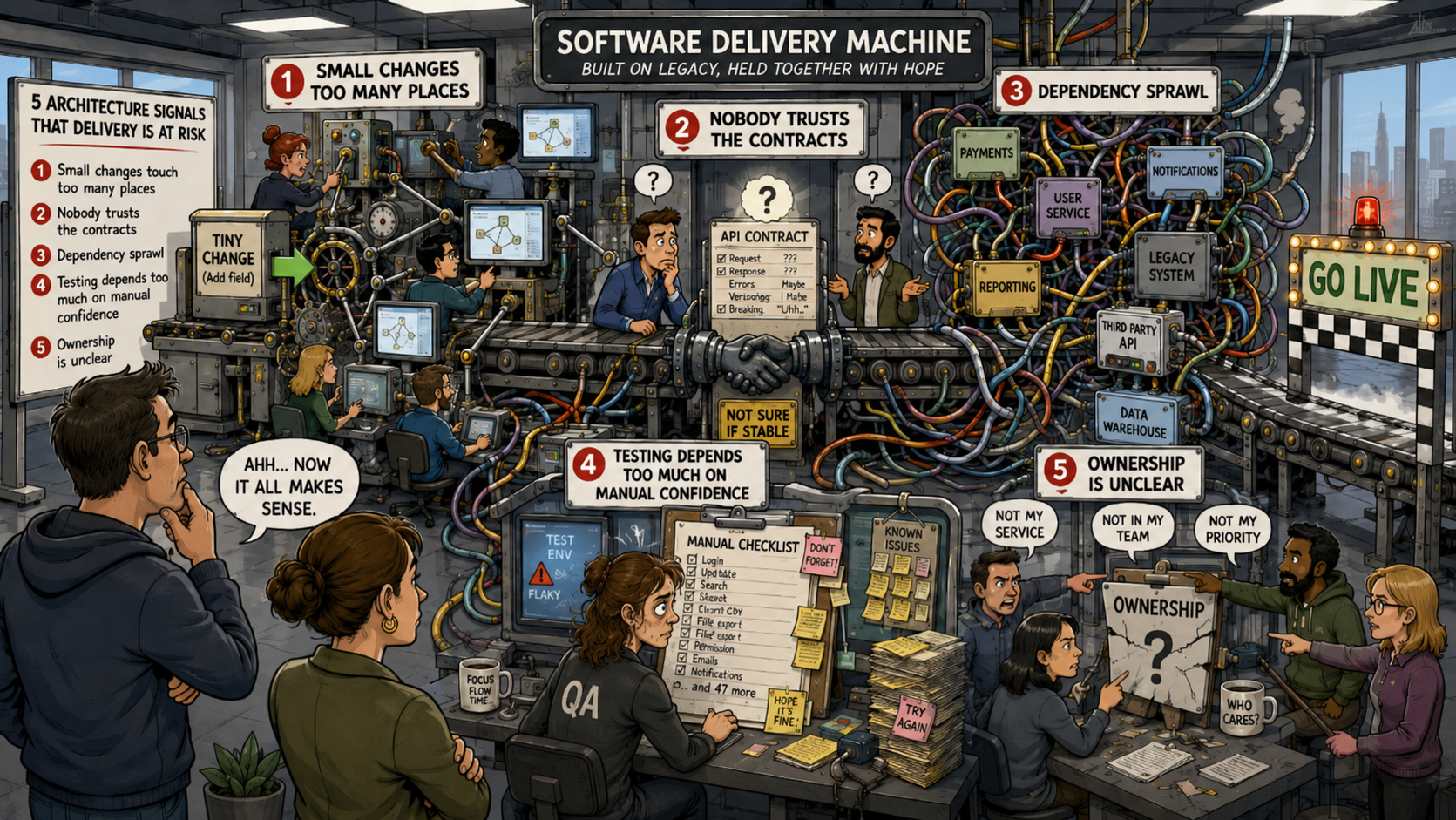
Signal 1: Small changes require touching too many places
One of the clearest signs of delivery issues is when small business changes require modifications across too many parts of the system.
A pricing rule changes, but it affects quoting, invoices, reports, permissions, notifications, and several background jobs.
A customer status changes, but the team has to inspect five different places where status logic is partially duplicated.
A new operational exception is introduced, but nobody is fully sure which workflows will be affected.
This is more than just inconvenience. It means the system does not have clear ownership of its business concepts.
When a change spreads too widely, the team must spend time finding every affected area, reasoning through side effects, coordinating reviews, updating tests, and validating behavior manually. Delivery slows because every change carries hidden investigation work, and estimations become inaccurate because of the increasing difficulty predicting this hidden work.
The visible task might be small - The actual change surface is large.
This usually points to weak domain boundaries. The system may have grown organically, with business logic added wherever it was convenient at the time. That may have been acceptable in the early stages, but as the business grows, convenience becomes coupling.
The risk here is not only slower delivery. The real risk is that eventually the team starts avoiding change.
They become careful in the wrong way, because they have to. They delay improvements because they cannot predict side effects. They add patches instead of correcting structure. They preserve bad flows because touching them feels too dangerous.
This is how technical debt becomes operational debt.
Signal 2: No one trusts the contracts between parts of the system
A healthy system has boundaries and responsibilities that teams can trust.
A module, service, API, integration, or internal process should have a clear contract: what it expects, what it returns, what errors mean, who owns it, and what behavior other parts of the system can rely on.
When those contracts are unclear or unstable, delivery becomes negotiation.
Developers need to inspect actual implementation details instead of relying on documented behavior. Teams ask each other whether a field is always present, why some fields are sometimes optional, and sometimes mandatory, whether a status can be skipped, whether an integration retries automatically, whether an error means failure or delay, whether an endpoint is safe to call during peak hours.
This just adds friction to every change.
It also creates a dangerous kind of uncertainty: the system may work most of the time, but nobody can explain confidently why it works, under what circumstances it definitely will work, when it fails, or what another team is allowed to depend on.
That is a very serious delivery risk to have.
Unclear contracts are especially damaging in systems that involve multiple teams, vendors, operational workflows, or customer-facing processes. Every unclear contract becomes a coordination tax. Every undocumented assumption becomes a potential incident. Every failure ensures declining trust and increasing friction between teams.
The real business cost shows up during integration, UAT, production releases, onboarding, and incident response.
A team can compensate for unclear contracts for a while through experience and informal communication. But that does not scale. Once key people are unavailable, new developers join, vendors change, or the system expands, hidden knowledge will turn into delivery instability.
If the team has to ask around before changing anything important, the architecture is not carrying enough knowledge.
Signal 3: Dependency sprawl is slowing every decision
Dependency sprawl happens when too many parts of the system depend on too many other parts without a clear reason, hierarchy, or ownership model.
This can happen inside the codebase, across services, between teams, or between business processes.
At first, it may not look that severe. A few shortcuts are taken out of what seems necessity. A module reaches into another module directly. A report queries production tables in a way nobody intended. A workflow depends on data from an integration that was never designed as a source of truth. A background job quietly updates state that another part of the system assumes it controls.
Each shortcut solves an immediate problem, but creates a new one on the long term: they create a system where nobody can make decisions locally anymore.
Before changing one area, the team must check who else depends on it. Before releasing one service, they must coordinate with several unrelated flows. Before cleaning up a field, they must determine whether some report, export, script, or vendor integration still uses it.
This is where delivery starts becoming slow in a way that planning tools cannot explain or identify.
The project plan may show tasks assigned to individual teams, but the architecture forces those teams into constant cross-dependency management. Each change becomes a small political and technical negotiation.
Dependency sprawl also makes prioritization harder.
Leadership may want to move quickly on a business-critical workflow, but the team cannot isolate the work. A seemingly contained initiative pulls in unrelated system areas because the architecture has allowed responsibilities to leak across boundaries.
This is why adding more people often fails.
If the system is too entangled, more people create more coordination overhead. The problem isn't capacity. The problem is that the architecture does not allow work to be separated cleanly.
Signal 4: Testing depends too much on manual confidence
A system that cannot be tested cleanly cannot be changed safely.
This doesn't mean every system needs a perfect automated test suite. That's not realistic for many legacy or fast-moving environments. But leadership should be concerned when release confidence depends mainly on manual inspection, developer memory, or a few people who “know where the risky parts are.”
That is not a quality strategy - That is institutional risk.
The warning signs are usually easy to recognize:
- The team avoids refactoring because they cannot prove what they broke.
- Regression testing takes too long and still misses important paths.
- Production bugs appear in workflows that were supposedly unrelated to the change.
- Developers rely on manual database checks to confirm behavior.
- Test environments do not reflect production behavior closely enough.
- Critical business rules are not covered by reliable tests.
- The team says “we tested the feature,” but not “we tested the affected system behavior.”
This is an architectural issue because testability is largely a result of system structure.
If business logic is scattered, hidden behind side effects, tightly coupled to infrastructure, or mixed directly into presentation and integration layers, testing becomes expensive and fragile. The result is slower delivery and declining confidence.
This also creates a negative loop.
Because testing is difficult, the team tests less than it should. Because the team tests less, changes become riskier. Because changes are risky, releases become slower. Because releases are slower, pressure increases. Because pressure increases, shortcuts become more attractive.
That loop unfortunately doesn't fix itself.
It needs deliberate and purposeful intervention.
The goal here is not to pause the business and create a perfect test architecture. That's usually unrealistic and more often than not even wasteful. The better move is to identify the highest-risk business flows and build testability around those first.
In practical terms, that means isolating critical business rules, creating reliable regression coverage for revenue-impacting workflows, stabilizing environments, and making release confidence less dependent on heroic manual effort.
Signal 5: Ownership is unclear at the system boundary level
Many organizations think they have ownership because tasks are assigned.
That however, is not enough.
Task ownership isn't the same as system ownership.
A developer may own a ticket. A team may own a sprint goal. A project manager may own a timeline. But who owns the behavior of a workflow across modules? Who owns the API contract? Who owns data consistency between systems? Who owns the operational consequences after release? Who owns the decision when two parts of the architecture are in conflict?
If the answers to these questions are unclear, delivery risk will keep increasing.
This problem becomes especially visible in growing teams. Early on, a small group can keep the whole system in their heads. Decisions happen informally. Everyone knows who to ask. Architectural boundaries can remain implicit.
That breaks down as soon as the system and team grows.
New developers need explicit ownership. Vendors need explicit interfaces. Operations needs explicit support paths. Leadership needs explicit accountability. Without those, technical decisions become scattered and reactive.
The system starts changing according to whoever touches it last, and the accountability is often assigned with it.
That is not architecture. That is accumulation.
Unclear ownership also creates review bottlenecks. If nobody is clearly responsible, every meaningful change requires broad consultation. If too many people are responsible, nobody has real authority. If one senior person unofficially owns everything, the organization has created a bottleneck disguised as expertise.
The result is predictable: slower delivery, inconsistent decisions, overloaded senior staff, and a system that becomes harder to reason about every quarter.
Why these signals are often missed
These architecture signals are easy to miss because none of them look dramatic at first, or are simply going unrecognized altogether.
The team is still delivering. The system still works. Customers may not be complaining yet. The backlog still moves. Most meetings still sound normal.
But the cost of change is rising, and keeps rising.
That is the point leadership needs to understand.
Architectural delivery risk is not measured only by outages or failed releases. It is also measured by how much effort is required to safely deliver the next meaningful change.
A system can be operational today and still be structurally unprepared for what the business expects from it tomorrow.
This is also the point where many companies fool themselves. They assume that because the system is currently functioning, the architecture is acceptable, and maintaining architecture is purely optional. That is not necessarily true. The better question is whether the architecture still supports the business direction, and who will keep those objectives aligned?
Can the team add features without excessive side effects?
Can the system absorb operational changes?
Can new developers become productive without relying on tribal knowledge?
Can releases happen safely without extraordinary coordination?
Can the business make decisions without discovering that every option is blocked by old technical compromises?
If the answer to any of these questions is vague, the organization may already be paying an architectural tax. It just hasn't been named, or even recognized yet.
The diagnostic: separating normal complexity from architectural risk
Not every slow delivery problem is an architecture problem.
Some systems are complex because the business is complex. Some workflows genuinely require careful coordination. Some releases are slow because regulatory, operational, or customer constraints make them slow. Architecture should not be blamed for everything.
The diagnostic question is whether the complexity is essential or accidental.
Essential complexity comes from the business reality. It may be unavoidable.
Accidental complexity comes from how the system has been allowed to grow. It can often be reduced.
A useful architectural diagnostic should answer questions like:
- Which business concepts have unclear ownership in the code or system design?
- Which workflows require changes across too many unrelated areas?
- Which modules, services, or integrations have contracts that teams do not fully trust?
- Where are business rules duplicated?
- Which dependencies make releases slower than they should be?
- Which areas cannot be tested without excessive manual effort?
- Which parts of the system rely on one or two people’s memory?
- Which recent defects were caused by unexpected side effects?
- Which technical decisions are repeatedly reopened because ownership is unclear?
- Which system boundaries no longer match how the business operates?
The point of this review is not to produce a beautiful architecture document.
The point is to identify where the architecture is now constraining delivery and where targeted intervention would improve speed, safety, and predictability.
The intervention: what to fix first
The wrong response to architectural risk is to announce a large rebuild without diagnosis. That is usually an expensive way to replace one risk with another.
A better intervention starts smaller and more deliberately.
The first step is to identify the delivery-critical flows.
Not every part of the system deserves equal attention. The business should focus first on workflows that directly affect revenue, operations, customer experience, compliance, or release stability. These are the areas where architectural drag has the highest business cost.
The second step is to map change friction.
Look at recent work. Which changes took longer than expected? Which ones caused defects? Which ones required too many approvals, too much coordination, or too much investigation? Which parts of the system are developers afraid to touch?
That evidence is more useful than abstract architecture debate.
The third step is to define ownership boundaries.
This means deciding which team, module, service, or vendor owns which business capability, contract, data responsibility, and operational behavior. These boundaries should be practical. They do not need to be theoretically perfect. They need to reduce confusion and make decisions easier.
The fourth step is to stabilize the riskiest contracts.
APIs, events, shared data structures, integration points, and internal module interfaces should be made explicit where they matter most. A contract does not need to be complicated, but it must be reliable enough that teams can build against it without constant clarification.
The fifth step is to improve testability around critical behavior.
Start with the workflows where failure is expensive. Build regression coverage, isolate business rules where possible, reduce dependence on manual validation, and make production-like behavior easier to verify before release.
The sixth step is to reduce dependency sprawl gradually.
This may involve extracting logic into clearer modules, removing duplicated rules, introducing anti-corruption layers around unstable integrations, or creating cleaner interfaces between parts of the system. The goal is not architectural purity. The goal is to make future change less expensive.
Trade-offs and risks
There are always trade-offs when correcting architectural delivery risk.
The most obvious one is that structural improvement competes with feature delivery. Some leadership teams resist this because they see architecture work as internal engineering cleanup.
That view is often too narrow.
If the current structure is slowing every meaningful change, then architecture work is not separate from delivery. It is work required to restore delivery capacity.
However, this does not mean every architecture improvement is justified. Teams can easily overcorrect. They may start redesigning parts of the system that are not actually constraining the business. They may chase fashionable patterns. They may create abstraction for its own sake. They may turn a practical stabilization effort into a technical ideology project.
That is waste.
The work must stay tied to business impact.
Another trade-off is that making ownership explicit may reveal uncomfortable gaps. Some teams may discover they depend on systems nobody clearly owns. Some vendors may be operating in areas where internal accountability is weak. Some senior developers may be carrying too much hidden responsibility.
This can create friction, but it is useful friction.
The organization is not becoming more complicated. It is finally seeing the complexity it was already carrying.
Architecture improvement is not about making diagrams cleaner.It is about making change safer, faster, and easier to own.
There is also a sequencing risk. Trying to fix too much at once can paralyze delivery. The better approach is controlled improvement: one critical workflow, one boundary, one contract, one testability gap, one dependency problem at a time.
Architecture work should reduce operational drag, not become a new source of it.
Implementation checklist
This checklist can help leadership and engineering teams identify whether architectural risk is starting to affect delivery:
- Review the last five to ten delayed or difficult changes and identify repeated friction patterns.
- Identify business-critical workflows where small changes require touching many parts of the system.
- Locate duplicated business rules, especially around pricing, permissions, status changes, operational exceptions, and reporting.
- List system contracts that teams do not fully trust or understand.
- Identify integrations, modules, or data flows without clear ownership.
- Map dependencies that regularly slow releases or create coordination overhead.
- Find areas where release confidence depends heavily on manual testing or individual memory.
- Identify parts of the system that developers avoid changing.
- Review production incidents and escaped defects for architectural causes, not only immediate technical causes.
- Define ownership for critical workflows, APIs, data responsibilities, and operational handoffs.
- Stabilize the contracts that affect the most teams or highest-risk workflows.
- Build automated or repeatable regression checks around revenue-impacting and operations-critical behavior.
- Avoid broad rewrites unless the diagnostic clearly proves that stabilization is no longer economically sensible.
- Track whether changes become easier, safer, and more predictable after each intervention.
Useful KPIs may include change lead time, escaped defects, release rollback frequency, number of components touched per feature, time spent on regression testing, incident recurrence, dependency-related blockers, and decision aging around technical ownership.
What 'good' looks like after stabilization
After the right architectural interventions, delivery should feel less fragile.
That does not mean the system becomes perfect. It means the team can make important changes with more confidence and less unnecessary coordination.
Good architecture in this context is practical and visible through delivery behavior.
Teams understand where business rules live. Contracts are explicit enough to be trusted. Critical workflows have clear owners. The most important behavior can be tested without relying entirely on manual confidence. New developers can reason about the system faster. Releases require less heroism. Technical decisions stop circulating endlessly because ownership is clearer.
Most importantly, leadership gets better predictability.
Not because every estimate becomes perfect, but because the team is no longer fighting hidden structural drag in every meaningful change.
A healthy architecture does not eliminate complexity. It contains it.
It allows the business to keep moving without making every new requirement feel like a dangerous negotiation with the past.
If your software delivery is slowing down and the usual explanations no longer hold, the problem may not be the backlog, the sprint process, or the team’s effort.
It may be the very system structure underneath them.
Binarika helps organizations diagnose architectural delivery risk, stabilize ownership boundaries, reduce dependency friction, and restore safer delivery patterns without defaulting to unnecessary rebuilds. A focused architecture and delivery review can often clarify whether the right next move is stabilization, modernization, or a deeper structural reset.